
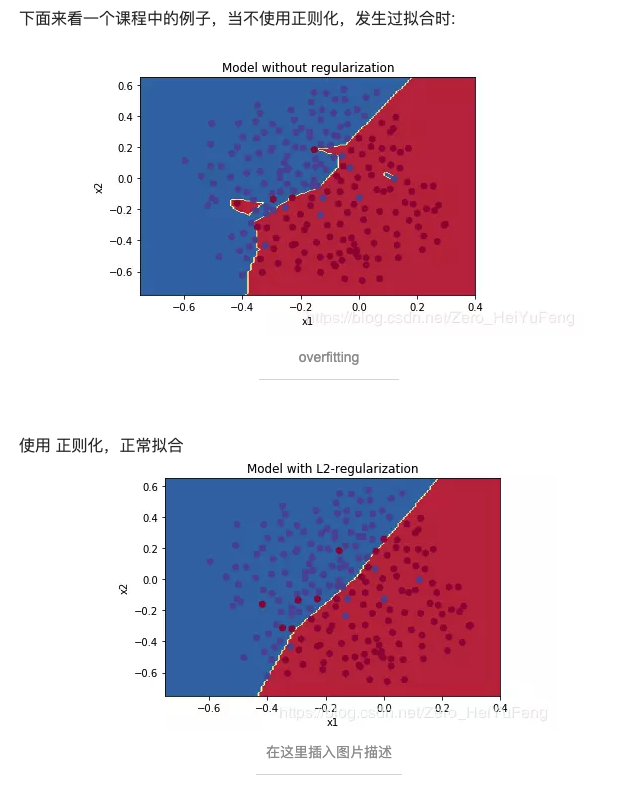
正则化的概念及原因
简单来说,正则化是一种为了减小测试误差的行为(有时候会增加训练误差)。我们在构造机器学习模型时,最终目的是让模型在面对新数据的时候,可以有很好的表现。当你用比较复杂的模型比如神经网络,去拟合数据时,很容易出现过拟合现象(训练集表现很好,测试集表现较差),这会导致模型的泛化能力下降,这时候,我们就需要使用正则化,降低模型的复杂度。
正则化的几种常用方法
- L1 & L2范数



- 数据增强

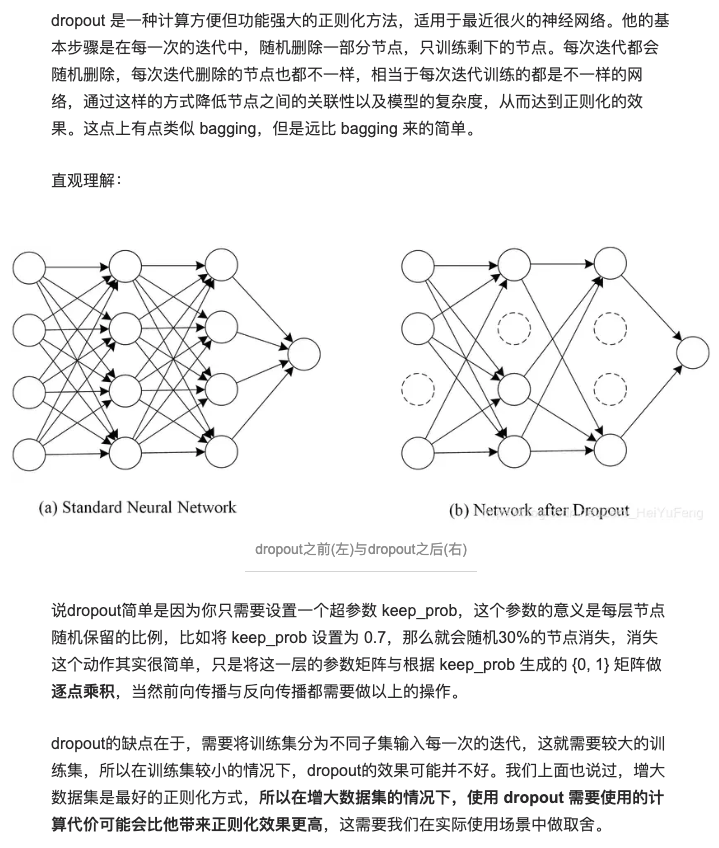
- dropout
- 提前终止训练
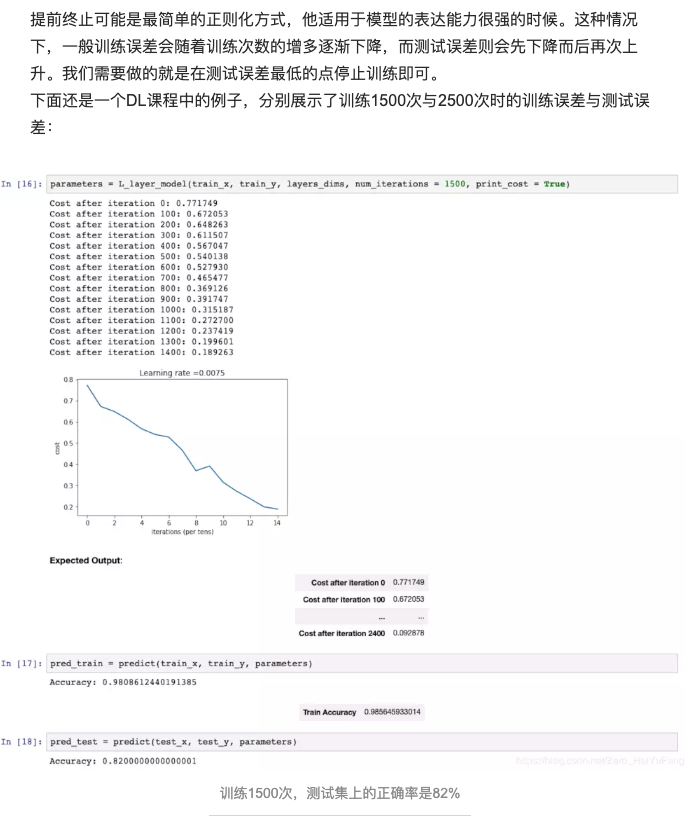
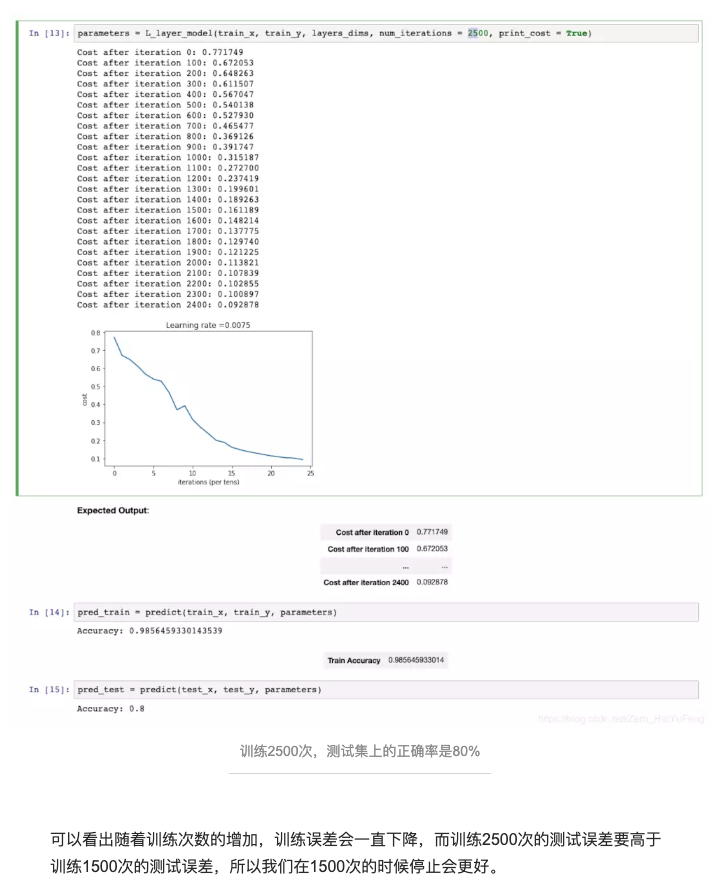
关于原文
原文来源于”简书“。 点击跳转




