
介绍
当我们需要手动复现算法时,很可能就需要靠自己手动仿造源作者设计的神经网络进行搭建,这里有两个非常好当工具,有了它,就不需要一步一步计算网络每一层当数据结构变化,大大便捷了网络当设计工作。
目录
pytorch-summary
项目地址:https://github.com/sksq96/pytorch-summary点击跳转 最简单的 pytorch 网络结构打印方法,也是最不依赖各种环境的一个轻量级可视化网络结构pytorch 扩展包 类似于Keras style的model.summary() 以前用过Keras的朋友应该见过,Keras有一个简洁的API来查看模型的可视化,这在调试网络时非常有用。这是一个准备在PyTorch中模仿相同的准系统代码。目的是提供补充信息,以及PyTorch中print(your_model)未提供的信息。
使用方法
- pip 下载安装 torchsummary
pip install torchsummaryorgit clone https://github.com/sksq96/pytorch-summary请注意,input_size是进行网络正向传递所必需的。
一个简单的例子
CNN for MNSIT
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # PyTorch v0.4.0
model = Net().to(device)
summary(model, (1, 28, 28))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 10, 24, 24] 260
Conv2d-2 [-1, 20, 8, 8] 5,020
Dropout2d-3 [-1, 20, 8, 8] 0
Linear-4 [-1, 50] 16,050
Linear-5 [-1, 10] 510
================================================================
Total params: 21,840
Trainable params: 21,840
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.06
Params size (MB): 0.08
Estimated Total Size (MB): 0.15
----------------------------------------------------------------
可视化 torchvision 里边的 vgg
import torch
from torchvision import models
from torchsummary import summary
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
vgg = models.vgg11_bn().to(device)
summary(vgg, (3, 224, 224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,792
BatchNorm2d-2 [-1, 64, 224, 224] 128
ReLU-3 [-1, 64, 224, 224] 0
MaxPool2d-4 [-1, 64, 112, 112] 0
Conv2d-5 [-1, 128, 112, 112] 73,856
BatchNorm2d-6 [-1, 128, 112, 112] 256
ReLU-7 [-1, 128, 112, 112] 0
MaxPool2d-8 [-1, 128, 56, 56] 0
Conv2d-9 [-1, 256, 56, 56] 295,168
BatchNorm2d-10 [-1, 256, 56, 56] 512
ReLU-11 [-1, 256, 56, 56] 0
Conv2d-12 [-1, 256, 56, 56] 590,080
BatchNorm2d-13 [-1, 256, 56, 56] 512
ReLU-14 [-1, 256, 56, 56] 0
MaxPool2d-15 [-1, 256, 28, 28] 0
Conv2d-16 [-1, 512, 28, 28] 1,180,160
BatchNorm2d-17 [-1, 512, 28, 28] 1,024
ReLU-18 [-1, 512, 28, 28] 0
Conv2d-19 [-1, 512, 28, 28] 2,359,808
BatchNorm2d-20 [-1, 512, 28, 28] 1,024
ReLU-21 [-1, 512, 28, 28] 0
MaxPool2d-22 [-1, 512, 14, 14] 0
Conv2d-23 [-1, 512, 14, 14] 2,359,808
BatchNorm2d-24 [-1, 512, 14, 14] 1,024
ReLU-25 [-1, 512, 14, 14] 0
Conv2d-26 [-1, 512, 14, 14] 2,359,808
BatchNorm2d-27 [-1, 512, 14, 14] 1,024
ReLU-28 [-1, 512, 14, 14] 0
MaxPool2d-29 [-1, 512, 7, 7] 0
Linear-30 [-1, 4096] 102,764,544
ReLU-31 [-1, 4096] 0
Dropout-32 [-1, 4096] 0
Linear-33 [-1, 4096] 16,781,312
ReLU-34 [-1, 4096] 0
Dropout-35 [-1, 4096] 0
Linear-36 [-1, 1000] 4,097,000
================================================================
Total params: 132,868,840
Trainable params: 132,868,840
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 181.84
Params size (MB): 506.85
Estimated Total Size (MB): 689.27
----------------------------------------------------------------
好处是我们可以很直观的看到我们一个 batch_size的 Tensor 输入神经网络的时候需要多到多少的空间,缺点呢就是我们不能直观的看到各层网络间的连接结构
HiddenLayer
项目地址:https://github.com/waleedka/hiddenlayer点击跳转 HiddenLayer是一个可以用于PyTorch,Tensorflow和Keras的神经网络图和训练指标的轻量级库。HiddenLayer简单易用,适用于Jupyter Notebook。它不是要取代高级工具,例如TensorBoard,而是用于高级工具对于任务来说太大的情况。
安装grazhviz
推荐使用 conda安装,一键配置其所需要的环境
conda install graphviz python-graphviz
- Otherwise:
Install GraphViz Then install the Python wrapper for GraphViz using pip:
pip install graphviz
pip install hiddenlayer
一个简单的例子
VGG16
import torch
import torchvision.models
import hiddenlayer as hl
# VGG16 with BatchNorm
model = torchvision.models.vgg16()
# Build HiddenLayer graph
# Jupyter Notebook renders it automatically
hl.build_graph(model, torch.zeros([1, 3, 224, 224]))
在可视化网络之前,我们先将 VGG 网络实例化,然后个 hiddenlayer 输入进去一个([1,3,224,224])的四阶张量(意思相当于一张224 * 224的 RGB 图片)
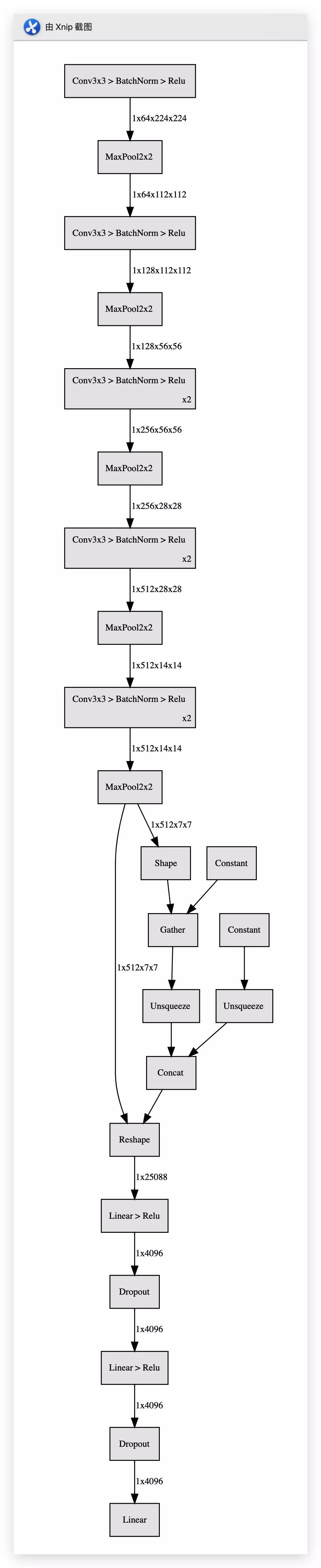
使用 transforms把残差块缩写表示
# Resnet101
device = torch.device("cuda")
print("device = ", device)
model = torchvision.models.resnet152().cuda()
# Rather than using the default transforms, build custom ones to group
# nodes of residual and bottleneck blocks.
transforms = [
# Fold Conv, BN, RELU layers into one
hl.transforms.Fold("Conv > BatchNorm > Relu", "ConvBnRelu"),
# Fold Conv, BN layers together
hl.transforms.Fold("Conv > BatchNorm", "ConvBn"),
# Fold bottleneck blocks
hl.transforms.Fold("""
((ConvBnRelu > ConvBnRelu > ConvBn) | ConvBn) > Add > Relu
""", "BottleneckBlock", "Bottleneck Block"),
# Fold residual blocks
hl.transforms.Fold("""ConvBnRelu > ConvBnRelu > ConvBn > Add > Relu""",
"ResBlock", "Residual Block"),
# Fold repeated blocks
hl.transforms.FoldDuplicates(),
]
# Display graph using the transforms above
resnet152=hl.build_graph(model, torch.zeros([1, 3, 224, 224]).cuda(), transforms=transforms)
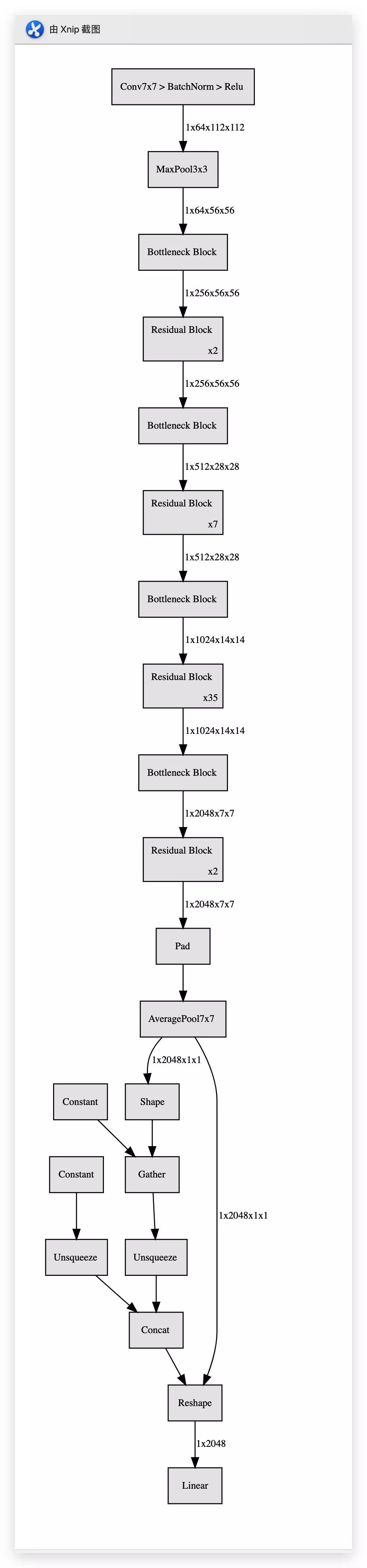
保存图片
resnet152.save("resnet152")
有了网络结构图,我们便会像,如何把我们的模型他训练的结果可视化出来呢? 比如我们经常在论文中看到这样的图:
import os
import time
import random
import numpy as np
import torch
import torchvision.models
import torch.nn as nn
from torchvision import datasets, transforms
import hiddenlayer as hl
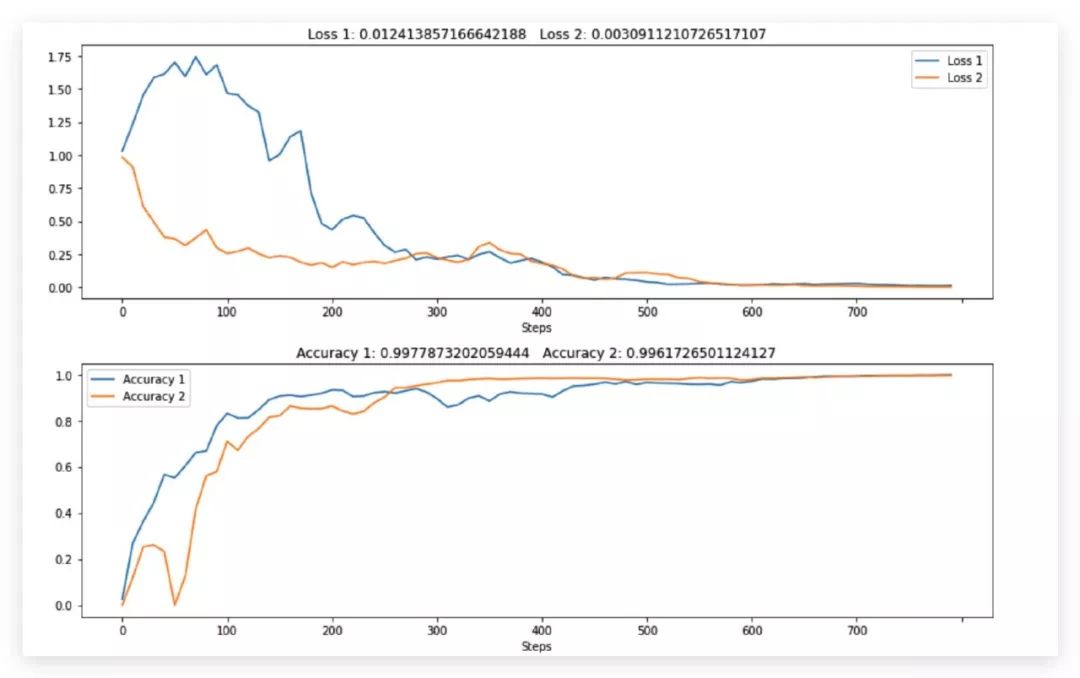
一个简单的回归的例子
# New history and canvas objects
history2 = hl.History()
canvas2 = hl.Canvas()
# Simulate a training loop with two metrics: loss and accuracy
loss = 1
accuracy = 0
for step in range(800):
# Fake loss and accuracy
loss -= loss * np.random.uniform(-.09, 0.1)
accuracy = max(0, accuracy + (1 - accuracy) * np.random.uniform(-.09, 0.1))
# Log metrics and display them at certain intervals
if step % 10 == 0:
history2.log(step, loss=loss, accuracy=accuracy)
# Draw two plots
# Encluse them in a "with" context to ensure they render together
with canvas2:
canvas2.draw_plot([history1["loss"], history2["loss"]],
labels=["Loss 1", "Loss 2"])
canvas2.draw_plot([history1["accuracy"], history2["accuracy"]],
labels=["Accuracy 1", "Accuracy 2"])
time.sleep(0.1)
序列化保存结果和加载
# Save experiments 1 and 2
history1.save("experiment1.pkl")
history2.save("experiment2.pkl")
# Load them again. To verify it's working, load them into new objects.
h1 = hl.History()
h2 = hl.History()
h1.load("experiment1.pkl")
h2.load("experiment2.pkl")
利用饼状图来显示
class MyCanvas(hl.Canvas):
"""Extending Canvas to add a pie chart method."""
def draw_pie(self, metric):
# Method name must start with 'draw_' for the Canvas to automatically manage it
# Use the provided matplotlib Axes in self.ax
self.ax.axis('equal') # set square aspect ratio
# Get latest value of the metric
value = np.clip(metric.data[-1], 0, 1)
# Draw pie chart
self.ax.pie([value, 1-value], labels=["Accuracy", ""])
history3 = hl.History()
canvas3 = MyCanvas() # My custom Canvas
# Simulate a training loop
loss = 1
accuracy = 0
for step in range(400):
# Fake loss and accuracy
loss -= loss * np.random.uniform(-.09, 0.1)
accuracy = max(0, accuracy + (1 - accuracy) * np.random.uniform(-.09, 0.1))
if step % 10 == 0:
# Log loss and accuracy
history3.log(step, loss=loss, accuracy=accuracy)
# Log a fake image metric (e.g. image generated by a GAN)
image = np.sin(np.sum(((np.indices([32, 32]) - 16) * 0.5 * accuracy) ** 2, 0))
history3.log(step, image=image)
# Display
with canvas3:
canvas3.draw_pie(history3["accuracy"])
canvas3.draw_plot([history3["accuracy"], history3["loss"]])
canvas3.draw_image(history3["image"])
time.sleep(0.1)
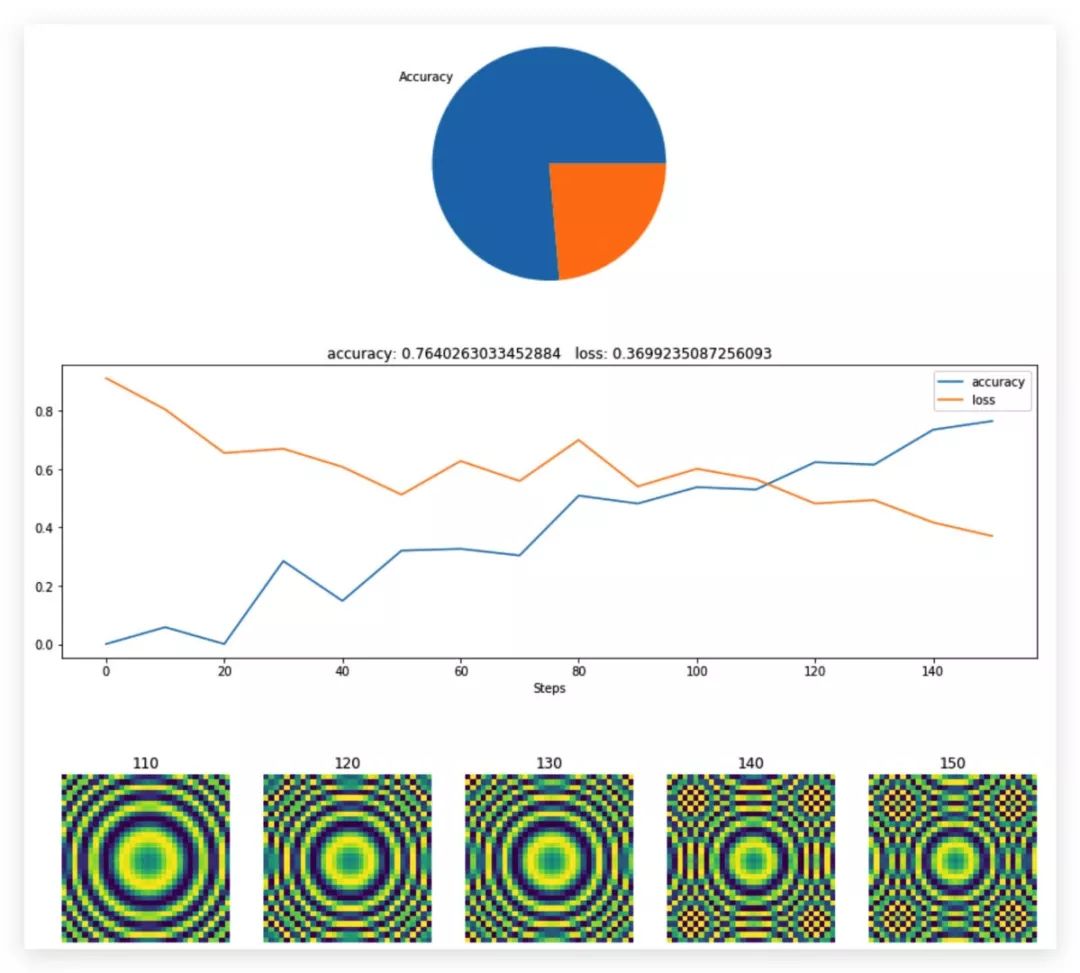
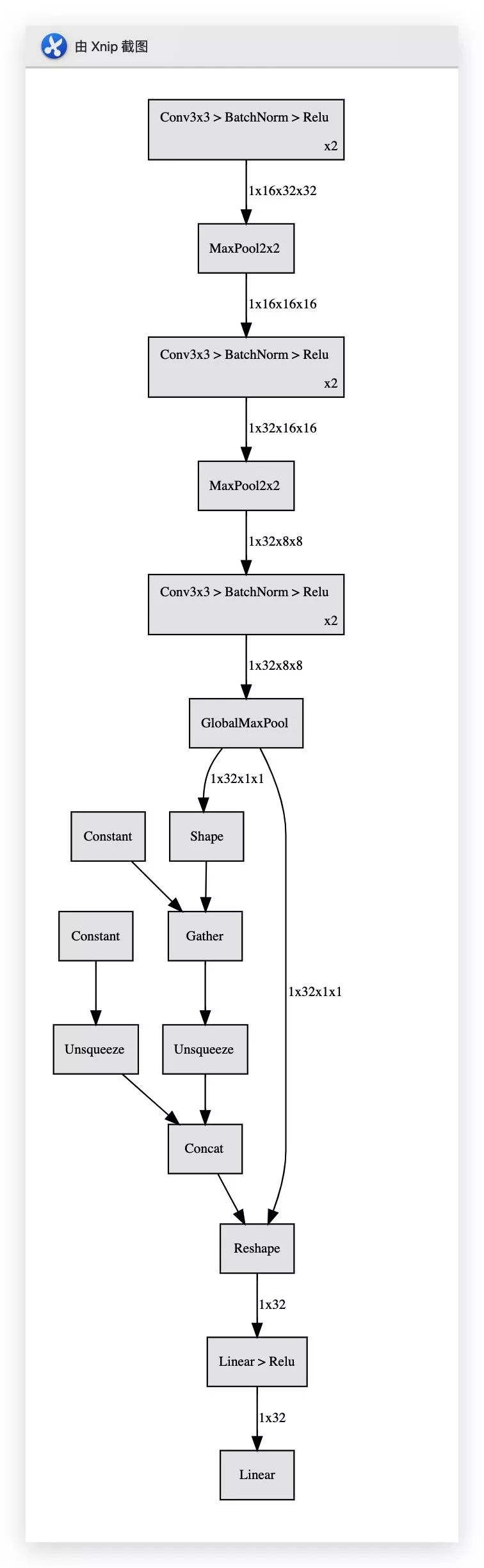
手动搭一个简单的分类网络
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
import torchvision
import torchvision.transforms as transforms
import numpy as np
import os
import argparse
# Simple Convolutional Network
class CifarModel(nn.Module):
def __init__(self):
super(CifarModel, self).__init__()
self.c2d=nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.features = nn.Sequential(
nn.BatchNorm2d(16),
nn.ReLU(),
nn.Conv2d(16, 16, kernel_size=3, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.AdaptiveMaxPool2d(1)
)
self.classifier = nn.Sequential(
nn.Linear(32, 32),
# TODO: nn.BatchNorm2d(32),
nn.ReLU(),
nn.Linear(32, 10))
def forward(self, x):
x_0=self.c2d(x)
x1 = self.features(x_0)
self.feature_map=x_0
x2 = x1.view(x1.size(0), -1)
x3 = self.classifier(x2)
return x3
model = CifarModel().cuda()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
#show parameter
summary(model, (3, 32, 32))
hl.build_graph(model,torch.zeros([1,3,32,32]).cuda())
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 32, 32] 448
BatchNorm2d-2 [-1, 16, 32, 32] 32
ReLU-3 [-1, 16, 32, 32] 0
Conv2d-4 [-1, 16, 32, 32] 2,320
BatchNorm2d-5 [-1, 16, 32, 32] 32
ReLU-6 [-1, 16, 32, 32] 0
MaxPool2d-7 [-1, 16, 16, 16] 0
Conv2d-8 [-1, 32, 16, 16] 4,640
BatchNorm2d-9 [-1, 32, 16, 16] 64
ReLU-10 [-1, 32, 16, 16] 0
Conv2d-11 [-1, 32, 16, 16] 9,248
BatchNorm2d-12 [-1, 32, 16, 16] 64
ReLU-13 [-1, 32, 16, 16] 0
MaxPool2d-14 [-1, 32, 8, 8] 0
Conv2d-15 [-1, 32, 8, 8] 9,248
BatchNorm2d-16 [-1, 32, 8, 8] 64
ReLU-17 [-1, 32, 8, 8] 0
Conv2d-18 [-1, 32, 8, 8] 9,248
BatchNorm2d-19 [-1, 32, 8, 8] 64
ReLU-20 [-1, 32, 8, 8] 0
AdaptiveMaxPool2d-21 [-1, 32, 1, 1] 0
Linear-22 [-1, 32] 1,056
ReLU-23 [-1, 32] 0
Linear-24 [-1, 10] 330
================================================================
Total params: 36,858
Trainable params: 36,858
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 1.27
Params size (MB): 0.14
Estimated Total Size (MB): 1.42
----------------------------------------------------------------
加载数据
# Data
print('==> Preparing data..')
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
==> Preparing data..
Files already downloaded and verified
Files already downloaded and verified
train_dataset.data Tensor uint8 (50000, 32, 32, 3) min: 0.000 max: 255.000
train_dataset.labels list len: 50000 [6, 9, 9, 4, 1, 1, 2, 7, 8, 3]
test_dataset.data Tensor uint8 (10000, 32, 32, 3) min: 0.000 max: 255.000
test_dataset.labels list len: 10000 [3, 8, 8, 0, 6, 6, 1, 6, 3, 1]
训练分类器
step = (0, 0) # tuple of (epoch, batch_ix)
cifar_history = hl.History()
cifar_canvas = hl.Canvas()
# Training loop
for epoch in range(10):
train_iter = iter(trainloader)
for batch_ix, (inputs, labels) in enumerate(train_iter):
# Update global step counter
step = (epoch, batch_ix)
optimizer.zero_grad()
inputs = inputs.to(device)
labels = labels.to(device)
# forward + backward + optimize
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# Print statistics
if batch_ix and batch_ix % 100 == 0:
# Compute accuracy
pred_labels = np.argmax(outputs.detach().cpu().numpy(), 1)
accuracy = np.mean(pred_labels == labels.detach().cpu().numpy())
# Log metrics to history
cifar_history.log((epoch, batch_ix),
loss=loss, accuracy=accuracy,
conv1_weight=model.c2d.weight,
feature_map=model.feature_map[0,1].detach().cpu().numpy())
# Visualize metrics
with cifar_canvas:
cifar_canvas.draw_plot([cifar_history["loss"], cifar_history["accuracy"]])
cifar_canvas.draw_image(cifar_history["feature_map"])
cifar_canvas.draw_hist(cifar_history["conv1_weight"])
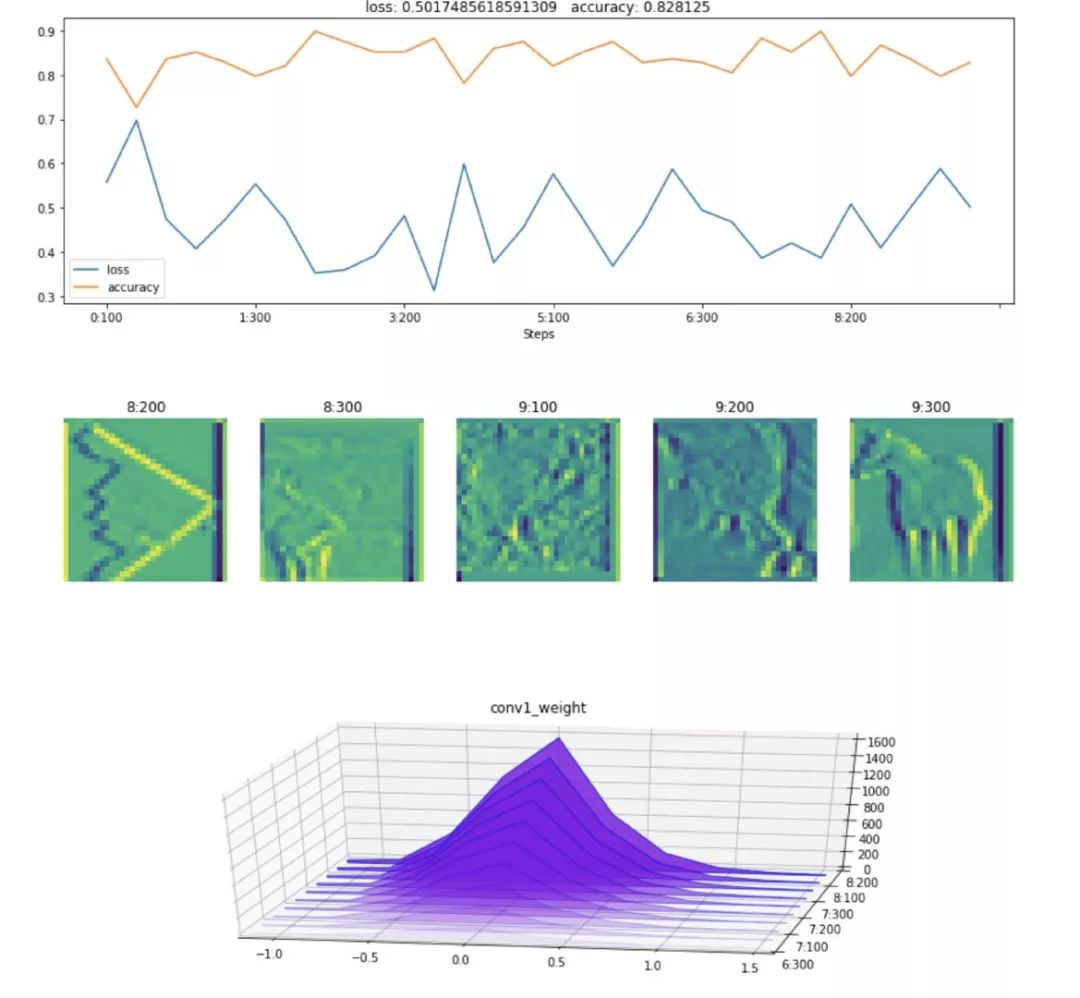
想要更多用法,可以去项目地址里去学习。
关于原文
文章内容来源于微信公众号点击跳转




