
背景
- 既然可以通过初试化和归一化(BN层)解决梯度弥散或爆炸的问题,那Resnet提出的那条通路是在解决什么问题呢? 在He的原文中有提到是解决深层网络的一种退化问题,但并明确说明是什么问题!
精解
- 个人认为这个理解比较简单易懂
- 一方面: ResNet解决的不是梯度弥散或爆炸问题,kaiming的论文中也说了:臭名昭著的梯度弥散/爆炸问题已经很大程度上被normalized initialization and intermediate normalization layers解决了;另一方面: 由于直接增加网络深度的(plain)网络在训练集上会有更高的错误率,所以更深的网络并没有过拟合,也就是说更深的网络效果不好,是因为网络没有被训练好,至于为啥没有被训练好,个人很赞同前面王峰的答案中的解释。
- 在ResNet中,building block:
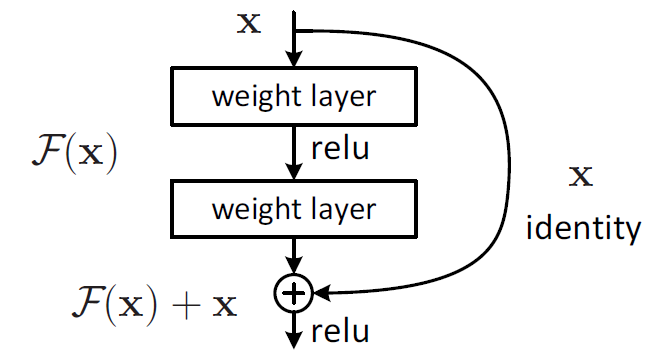
- H(x)是期望拟合的特征图,这里叫做desired underlying mapping
- 一个building block要拟合的就是这个潜在的特征图
- 当没有使用残差网络结构时,building block的映射F(x)需要做的就是拟合H(x)
- 当使用了残差网络时,就是加入了skip connection 结构,这时候由一个building block 的任务由: F(x) := H(x),变成了F(x) := H(x)-x
- 对比这两个待拟合的函数,文中说假设拟合残差图更容易优化,也就是说:F(x) := H(x)-x比F(x) := H(x)更容易优化,接下来举了一个例子,极端情况下:desired underlying mapping要拟合的是identity mapping,这时候残差网络的任务就是拟合F(x): 0,而原本的plain结构的话就是F(x) : x,而F(x): 0任务会更容易,原因是:resnet(残差网络)的F(x)究竟长什么样子?
- F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F’(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F’和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F’的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器
来源:知乎 链接:https://www.zhihu.com/question/64494691/answer/271335912点击跳转




